







Ahmedabad
(Head Office)Address : 506, 3rd EYE THREE (III), Opp. Induben Khakhrawala, Girish Cold Drink Cross Road, CG Road, Navrangpura, Ahmedabad, 380009.
Mobile : 8469231587 / 9586028957
E-mail: dics.upsc@gmail.com
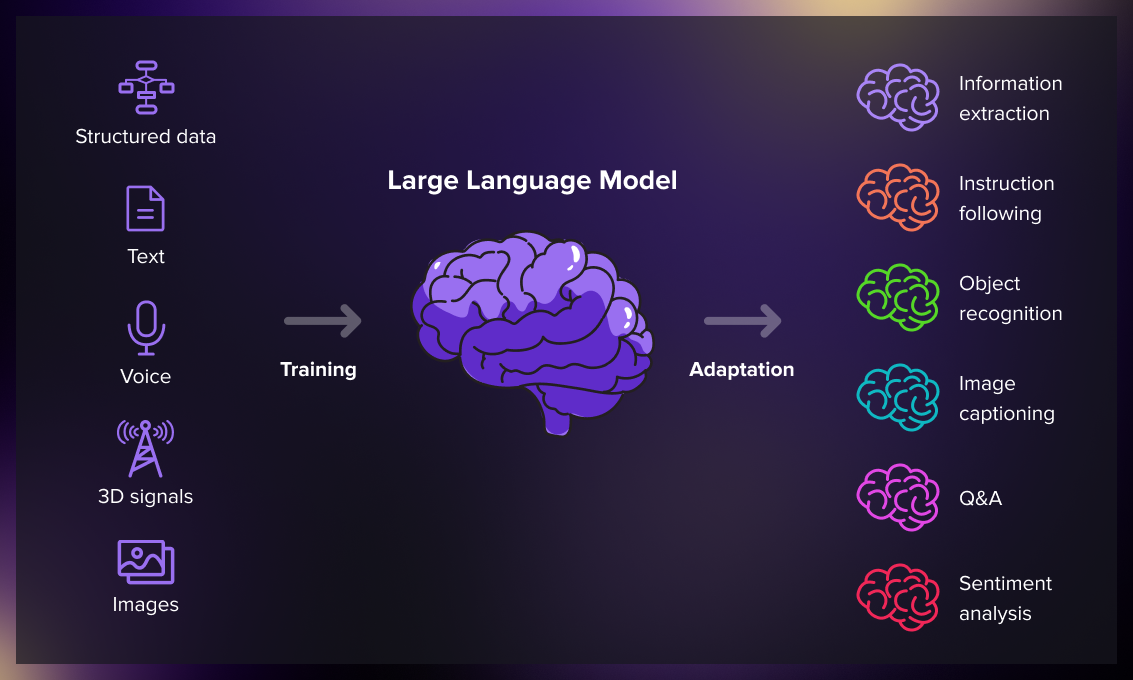
Large Language Models
News: The ability of Generative AI models to “converse” with humans and predict the next word or sentence is due to something known as the Large Language Model, or LLM.
What are LLM?
• A large language model (LLM) is a remarkable type of language model known for its ability to achieve general-purpose language generation and understanding. These models acquire their capabilities by learning statistical relationships from vast amounts of text documents during a computationally intensive self-supervised and semi-supervised training process.
How Many types of LLMs are there?
• Pre-training models: These models, such as GPT-3/GPT-3.5, T5, and XLNet, are trained on vast amounts of data during the pre-training phase. They learn a wide range of language patterns and structures, making them versatile for various natural language processing (NLP) tasks
• Foundation models: A recent concept popularized at Stanford, where LLMs are trained on broad data at a large scale. These models serve as foundational building blocks for more specialized models.
• Autoregressive language models: Examples include GPT (Generative Pre-trained Transformer). These models generate sentences word-by-word, left to right, predicting the next token based on the context
• Transformer-based: LaMDA or Gemini (formerly Bard) are transformer-based as they use a specific type of neural network architecture for language processing.
• Encoder-decoder: Models that encode input text into a representation and then decode it into another language or format.
• Open-source: LLaMA2, BlOOM, Google BERT, Falcon 180B, OPT-175 B are some open-source LLMs
• Closed-source: Claude 2, Bard, GPT-4.
How do LLMs work?
• Word Vectors: LLMs represent words using a long list of numbers called a “word vector”. For example, the word “cat” might be represented as a vector like [0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
• Transformers and Self-Attention: A key development in language modeling was the introduction of Transformers, an architecture designed around the idea of attention. This made it possible to process longer sequences by focusing on the most important part of the input.
• Training: LLMs are trained using massive datasets. They learn to predict the next word in a sequence based on the context provided by the previous words. This is why they require huge amounts of text data.
• Generation: Once trained, LLMs can generate new content, such as essays or articles, that are similar in style to the training data.
Applications of LLMs:
• Translation: LLMs can translate written texts. Some studies suggest that LLMs like GPT-4 perform competitively against commercial translation products.
• Malware Analysis: LLMs can be used for malware analysis. For instance, Google’s cybersecurity LLM, SecPaLM, scans and explains the behavior of scripts to determine whether they’re malicious.
• Content creation, virtual assistants and customer support
• Healthcare, finance and market/advertising

Address : 506, 3rd EYE THREE (III), Opp. Induben Khakhrawala, Girish Cold Drink Cross Road, CG Road, Navrangpura, Ahmedabad, 380009.
Mobile : 8469231587 / 9586028957
E-mail: dics.upsc@gmail.com
Address: A-306, The Landmark, Urjanagar-1, Opp. Spicy Street, Kudasan – Por Road, Kudasan, Gandhinagar – 382421
Mobile : 9723832444 / 9723932444
E-mail: dics.gnagar@gmail.com
Address: 2nd Floor, 9 Shivali Society, L&T Circle, opp. Ratri Bazar, Karelibaugh, Vadodara, 390018
Mobile : 9725692037 / 9725692054
E-mail: dics.vadodara@gmail.com
Address: 403, Raj Victoria, Opp. Pal Walkway, Near Galaxy Circle, Pal, Surat-394510
Mobile : 8401031583 / 8401031587
E-mail: dics.surat@gmail.com
Address: 303,305 K 158 Complex Above Magson, Sindhubhavan Road Ahmedabad-380059
Mobile : 9974751177 / 8469231587
E-mail: dicssbr@gmail.com
Address: 57/17, 2nd Floor, Old Rajinder Nagar Market, Bada Bazaar Marg, Delhi-60
Mobile : 9104830862 / 9104830865
E-mail: dics.newdelhi@gmail.com